
The importance of your data layout
Structure of Arrays vs Array of Structures

Today I thought we could go a bit more low-level and look at some of the fundamentals of data processing. I find that most topics on the subject of data layout tend to get super technical, “jargony” and just hard to digest. So for now we’ll only start scratching the surface. My hope is to get you excited about the potential locked away beneath the monolith of abstractions we have learned to cherish.
Do note that most the examples I’m going to use are here for demonstration purposes. Naturally, there are ways to optimise them differently. However, I’m hoping to give you a tool that you can use in situations where other means are insufficient.
Basics
Code is a tool that we Software Engineers use to solve problems. Usually, we use some high-level, easy-to-read-and-write language to instruct a computer to do certain things in a certain order. Regardless of the language or the domain, at the end of the day our code takes some input and transform it into some output. More specifically, it takes data in some arbitrary format and morphs it into some other.
It’s important to understand that how we package that input data determines how the computer is going to act on it.
OOP
In a traditional object oriented manner, we model pieces of data based on real-life items. For example, if we wanted to model an instance of a metric (an encapsulation of some measure), we might use a structure like this:
class Metric:
value: float
name: str
time: datetime
# etc.Generally speaking, a single metric instance is not super useful to us. More often than not, we’d want to collect a bunch of these and do some aggregation on top. Imagine a scenario, where we want to keep track of the revenue we gain over time. Naturally, we’d create a new `Metric` instance every time we sold an item. However, just glancing at all the items sold in a huge table is not super useful to us. It’s very likely, that we’d like to do some aggregation on top of all or a subset of these. Maybe we want to look at the sum of the value of all the items sold in the last 12 months.
sum = 0
for metric in metrics.collect(name='item_sold_revenue', timestamp > 12 months ago):
sum += metric.value
print(sum)In the pseudo code above, we collect all the relevant metrics, iterate over them and add the value of each to a variable that we are interested in. Seems straight forward, right?
Well, there are some issues with this. While the program itself gives a correct result, we are instructing our computer to do a lot more work than necessary. The reason for this is our data layout.
The `metrics.collect` call returns an array of Metric object, otherwise known as an Array of Structures or Row-based format. This is the basis of our iteration. In such a layout, data in the memory will be fragmented based on what each structure looks like.
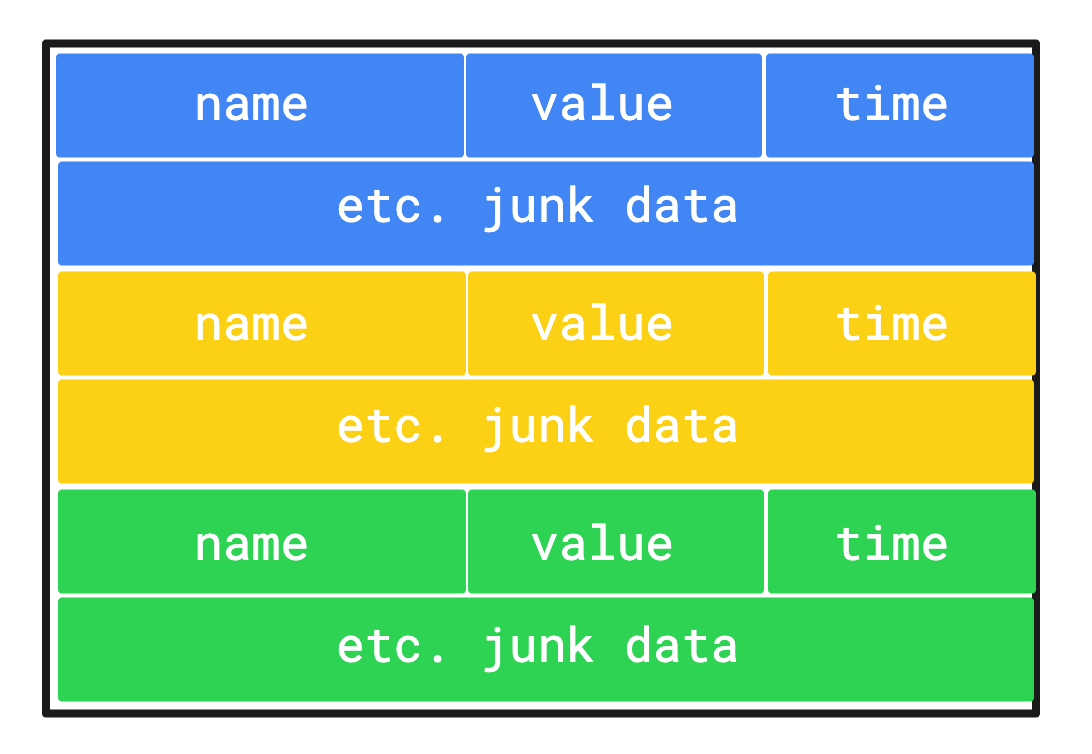
To calculate the sum of each of these items, the CPU has to figure out the right address to reach for the `value` field on each iteration. Moreover, in most cases our software won’t be able to utilise the SIMD operations (more on these later) of the CPU.
While on the surface this doesn’t seem like a big deal, when you scale this out to hundreds of millions or even billions of items, we can end up with seconds (!) being wasted on doing nothing. In the era of web applications, that’s a long time.
DOD
So what can we do? Fortunately, performance optimisation in compute-heavy applications has been a big topic in video game development for a long time now. The most prominent movement there is called Data Oriented Design, where instead of trying to model our data based on real-life things, we put in the effort to really understand how our data works and encompass it in structures that are better utilised by the underlying hardware.
This most typically results in a modelling technique called Structure of Arrays or Columnar Format. As a general rule of thumb, the more things you need to calculate on a given structure, the more beneficial this becomes. Let’s see why.
Our main data structure would change to something like the following:
class Metrics:
values: arr[float]
names: arr[str]
times: arr[datetime]
# etc.Going back to our example of finding sum of the value of all the items sold in the last 12 months, we’d have the following code:
revenues = metrics.filter(name='item_sold_revenue', timestamp > 12 months ago)
print(sum(revenues.values))On the surface not much has changed, but under the hood quite a bit happened. Arrays are generally allocated as a contiguous block of memory, which means for the instruction to work, we really only need to address the beginning of the block in memory and then offset it with the length of the data type for each iteration to get the next item. This is great, because not only can the CPU now utilise SIMD instructions, it can also prefetch data, since it knows exactly where to look for it. Sweet!
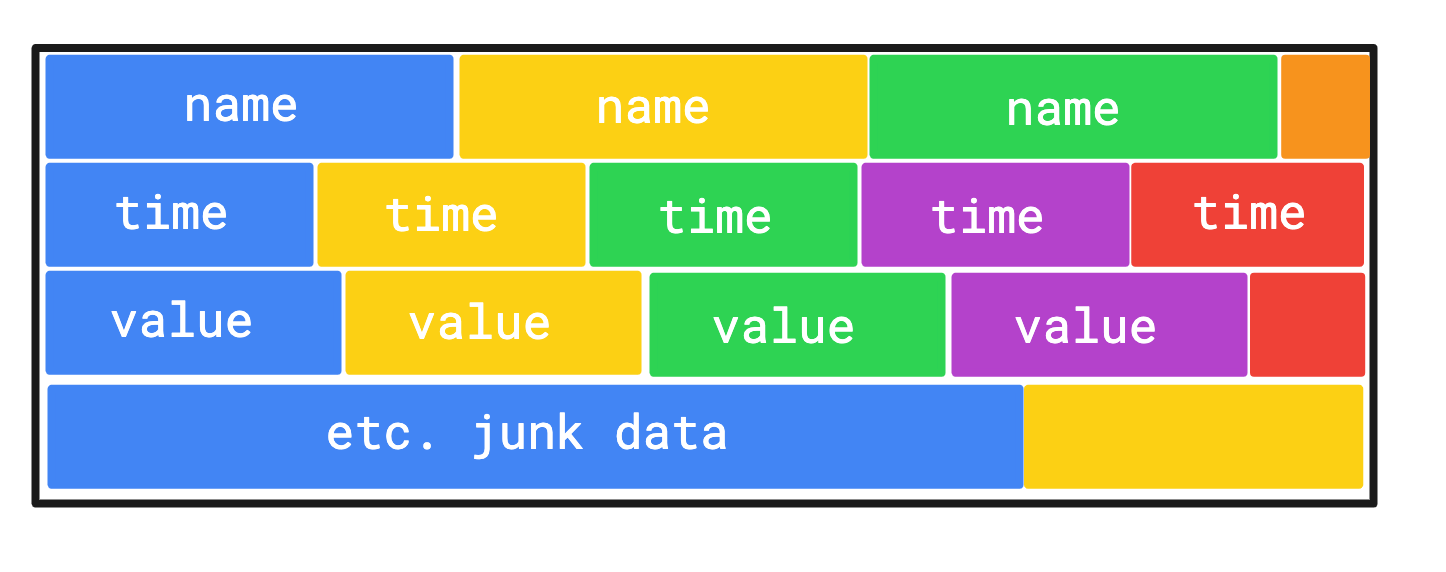
On top of this, if you have a structure where you need to do calculation on multiple fields, this type of layout makes it a lot simpler to do that work performantly in parallel. A typical example for this would doing transformations on a 3D object, where we need to modify its X,Y,Z,V positions.
Understanding SIMD
I’m not going into too much detail about how this works in this piece as I aim to make each post succinct and digestible. For now, we’ll just look at a surface level definition. This is also the time for me to plug the subscribe button — if you don’t want to miss out on these more advanced topics, please consider subscribing!
SIMD refers to Simple Instruction, Multiple Data. It’s a type of parallelisation, most typically deferred to the CPU where the same instruction gets executed on multiple datapoints at the same time. It’s also regarded as Vectorization. It’s extremely useful for arithmetics that can be done in parallel. Typically this is only available in lower level languages like C, C++, Rust, or through C-bindings in higher level languages — e.g. numpy for Python is a library that utilises SIMD instructions.
Why is it important?
Over the last decade or so we have seen a huge boom in data. Companies started focusing more and more on collecting data and trying to make sense of it. However, in many cases we still rely on archaic tooling and incorrect engineering practices to compute and display it. This leads to incredibly slow page load times — it’s not uncommon for a dashboard relying on hundreds of millions of records to have a load time of 30-60 seconds. I have seen cases where it took over 5 minutes to get 1 year’s of data displayed. This is a terrible user experience and is a big blocker for more companies that want to build analytics apps for the masses.
Luckily, there are some brilliant people in the space solving increasingly complex problems every day and so we are moving in the right direction. But I think it’s important that we understand the fundamentals that go into designing such systems.
When to use?
Applications that are very compute-heavy will typically benefit a lot from switching to Data Oriented Design. However, it’s important to understand that DOD has a lot smaller impact on higher-level languages, especially those that represent everything in memory as an object. Lower-level languages tend to give more freedom on how you can package your data. It does seem though, however, that even Java seems to receive some form of SIMD support in the future.
When not to use?
OLTP (online transactional processing) applications tend to get less benefit from going data oriented. These apps typically work with a single item or just a couple of them, making a more object oriented modelling approach more beneficial.
— B